 Представляю вам своего коллегу и друга Дмитрия Гордиевского – программиста от Б-га, с которым мне повезло вместе и очень плодотворно работать по обе стороны океана. Начали в Украине, продолжаем в США. Дмитрий и сейчас сильно помог мне своим антиспамовским плагином, о котором я и попросил его всем подробнее рассказать..
Представляю вам своего коллегу и друга Дмитрия Гордиевского – программиста от Б-га, с которым мне повезло вместе и очень плодотворно работать по обе стороны океана. Начали в Украине, продолжаем в США. Дмитрий и сейчас сильно помог мне своим антиспамовским плагином, о котором я и попросил его всем подробнее рассказать..
Всем нам, наверное, приходилось в той или иной мере сталкиваться со спам-роботами или хотя бы слышать об их существовании. Столкнулся с ними и я. В какой-то момент, устав от модерирования более сотни «мусорных» комментариев в день на форуме, я установил на него ‘captcha’ модуль. На какое-то время это помогло, но через пару недель поток спама возобновился, правда, в меньшем объеме.
Как известно, метод защиты ‘captcha’ заключается в том, что пользователю предоставляется сильно искаженное изображение текстовой строки, которую тот должен распознать и ввести соответствующие символы в поле ввода. Таким образом, человек подтверждает свое интеллектуальное превосходство над роботом и получает возможность для дальнейшей деятельности, чаще всего — это комментирование какой-либо статьи.
К сожалению, роботы «научились» распознавать такие изображения чуть ли не так же хорошо, как люди, по некоторым данным, около 85%. Тогда я решил поставить перед роботами такую задачу, которую было бы нелегко автоматизировать. По некоторым размышлениям, я пришел к выводу, что на сегодняшний день одной из самых надежных защит является распознавание визуальных конкретных объектов, а не просто символов. Такие защиты уже существуют, хотя большинство из них либо «выдают» искомый объект при помощи слов в описании, либо просят найти одинаковые объекты среди множества других. Теоретически, такие защиты тоже довольно легко взломать.
Тогда я решил привнести элемент неожиданности в свой алгоритм. Пусть это будут не одинаковые объекты (собаки среди кошек, например), а предметы из какой-либо категории, животные, например, или инструменты. Кроме того, пусть выбор будет предоставлен случайным образом и иногда все же пусть они (предметы), будут одинаковыми. Представьте себе, что в одном варианте вам предоставили пилу, молоток и 7 картинок, не имеющих ничего общего с инструментами. Вы выберете их, как наиболее близкие друг другу. А в другом варианте у вас будут две картинки с разными пилами, молоток, плоскогубцы и 5 остальных, не ‘инструментных’ картинок. По всей видимости, вы выберете пилы. А теперь представьте, что такую же задачу поставили перед роботом. Распознать, к примеру, все пилы или все молотки он, конечно, сможет, технологии сейчас очень продвинутые, и продвигаются еще дальше и быстрее. Но вот для того, чтобы собрать всю информацию о базе данных, включая категории и подкатегории, понадобится немало времени, да еще учитывая ограничение на количество ошибок с одного IP-адреса, которое легко ввести при необходимости.
Ну вот, а теперь представьте их разочарование, когда, собрав всю необходимую информацию и разбив-таки все картинки на категории-подкатегории, потирая руки от предвкушения, бедные роботы видят перед собой … абсолютно другую базу данных. Утилита формирования базы данных из 800 картинок работает приблизительно 30 секунд. Собирал я картинки на диск не больше трех дней, еще день ушел на дизайн категорий и подкатегорий. Роботам, осмелюсь предположить, сбор информации ‘по капле’ из вашей базы встанет как минимум в месяц. И в результате все равно они окажутся у разбитого корыта.
Таким образом, создав базу категорий и подкатегорий, сделав эту базу полуавтоматически (при помощи утилиты) пополняемой и модифицируемой, запрашивая выбрать не какой-либо конкретный объект, а два наиболее близко подходящих друг другу, можно, я уверен, довести надежность защиты до 100%. Что я и реализовал в своем плагине для WP (см скриншот ниже; для увеличения щелкните левой кнопкой мыши на картинку), под названием RUH — “aRe yoU a Human?” или “pRove yoU are a Human”
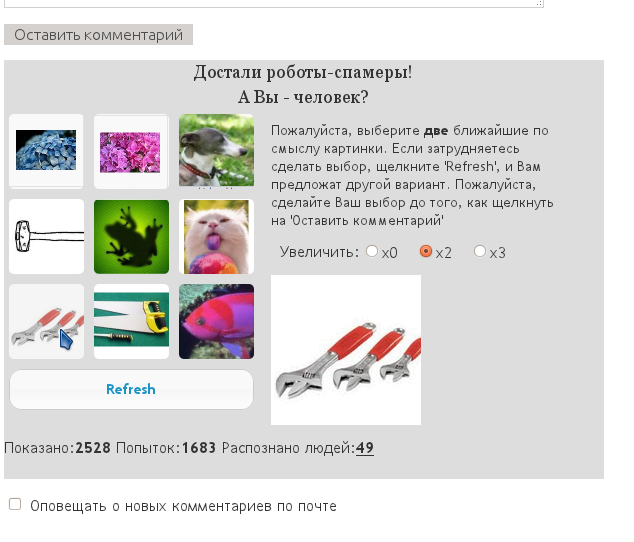 Вначале я испытал его на том форуме, который продолжал изнывать от спама. Спам исчез. Затем я попросил испытать его на блоге моего друга и коллеги Анатолия Мильнера. Выражаю ему огромную благодарность — ни минуты не сомневаясь, Анатолий установил плагин и предоставил мне статистику за месяц его работы. Статистика впечатлила: из 2400 предложений по выбору объектов было сделано 1600 попыток, и только 49 из них увенчались успехом. Предполагаю, что только они и оказались живыми людьми. Правда хозяин блога считает, что и среди попытавшихся были и такие, кто просто махнул рукой и не захотел решать мои уж слишком интеллектуальные задачки. Прав он или не прав, не знаю, но спам в блоге исчез полностью.
Вначале я испытал его на том форуме, который продолжал изнывать от спама. Спам исчез. Затем я попросил испытать его на блоге моего друга и коллеги Анатолия Мильнера. Выражаю ему огромную благодарность — ни минуты не сомневаясь, Анатолий установил плагин и предоставил мне статистику за месяц его работы. Статистика впечатлила: из 2400 предложений по выбору объектов было сделано 1600 попыток, и только 49 из них увенчались успехом. Предполагаю, что только они и оказались живыми людьми. Правда хозяин блога считает, что и среди попытавшихся были и такие, кто просто махнул рукой и не захотел решать мои уж слишком интеллектуальные задачки. Прав он или не прав, не знаю, но спам в блоге исчез полностью.
Воодушевленный результатами, я работаю сейчас над выводом своего плагина «в свет», в ближайшие дни он появится в WP библитеке плагинов. Следите за новостями на моей странице dimgord.com/ruh
Вы можете посмотреть сами и, «не отходя от кассы», испытать этот плагин (для этого придётся выйти из блога amilner.com, если вы там уже зарегистированы). Можете оставлять комментарии и по сути, и просто тестовые. В последнем случае, пожалуйста, не забудьте помечать их словом «Тест». Буду благодарен также за обычные (в не тестовом режиме) комментарии с любыми замечаниями и предложениями. Они мне сейчас очень помогут!

Комментарии
Powered by Facebook Comments

Тэги: bot, captcha, image-based captcha, malware, plugin, registration, spam, spam-filter, validation, WordPress, бот, плагин, регистрация, спам

Дима, то, что Ваш плагин работает эффективно, как уже было сказано, лично я хорошо убедился. А вот в части его оригинальности и непробиваемости вопросы всё-таки остались. Есть и другие вопросы. Давайте разберёмся. Думаю, что и тем читателям, которые заинтересуются Вашим плагином, это будет тоже полезно. Надеюсь, что они тоже подключатся к нашему разговору. Понимаю, что тут могут быть авторские секреты. Поэтому если мои (наши) вопросы будут их затрагивать, Вы об этом сразу же по ходу разговора будете говорить. Согласны?
Усложнение заданий бъет как по роботам, так и по пользователям. Слишком сложная фильтрация может кого-то отпугнуть от написания комментария.
Мне видится перспективным другой путь, через использование глобального рейтинга пользователей. Нетрудно строить рейтинг так, чтобы боты имели его низким. Например из анализа соцсвязей комментируемого — у бота обычно мало друзей. Идея оказалась не новой — более трех лет назад Иван Бегтин предлагал сделать такое в ЖЖ, а недавно нечто подобное уже сделали американцы.
С первым замечанием (бьёт по пользователям) согласен. Об этом я тоже говорил Дмитрию. Надеюсь, на него он ответит сам.
Что касается второго (рейтинги пользователей), то это уже по моей части:). Однако перед тем, как ответить, хотелось бы посмотреть на то, что «уже сделали американцы». Буду благодарен, Владимир, за ссылочку…
http://blogs.wsj.com/digits/20.....ok-attack/
Прочитал, спасибо. Об этом и я сообщал в своих новостных лентах в Фейсбук и/или Гугл+. Что можно на это Вам ответить? Во-первых, это не совсем то, вернее, совсем не то. Там говорится об опознании «плохих живых парней», которые создают за длительное время множество фиктивных акаунтов, а потом в некоторый момент их используют в своих целям. Дмитрий же предлагает механизм борьбы, прежде всего, с роботами (причём не обязательно ботами), которые, в частности, могут теми же вещами и заниматься, а могут и другими. Задачи, действительно, пересекаются, но полностью не покрывают друг друга. Во-вторых, у меня есть сомнения в возможности глобального ранжирования всего и вся в Интернете. Причём сомнения лежат, прежде всего, в социально-психологической, а не технической плоскости. Как Вы знаете, об этом я уже говорил здесь — http://www.amilner.com/2011/12/01/social-bicycle .
И, наконец, самое главное. Даже если я не прав в своих сомнениях, всё это дело завтрашнего, если даже не послезавтрашнего дня. Мы же с Дмитрием решаем практические задачи сегодняшнего дня. Ни один веб-издатель, ни большой, ни маленький не может сидеть, сложа руки, и ждать, когда некая светлая идея, наконец-то восторжествует во всей своей красе. Ведь даже то, на что Вы сослались, это только альфа, а когда она превратится в достойное бета, насколько будет эффективной, на каких платформах будет реализовано и с каких медийных платформ будет доступно, пока никто не знает. Со спамерами же и прочими «плохими парнями», будь они живыми или роботами, нам – практикам приходится сражаться сейчас, и ждать мы не можем. Почувствуйте разницу:)
Не ну с этим не спорю. Решение с помощью глобального рейтингования на порядки сложнее. Это действительно дело будущего. Просто рейтинги людей, они как гугл.карты, можно будет использовать в многих совершенно разных приложениях. Конкретно под спам-фильтры такое конечно никто создавать не будет.
Спасибо, Анатолий, спасибо, Владимир!
Да, говоря об усложнении, оно имеет место быть, как говорят в Одессе. Но это ‘золотое правило механики’, к сожалению. Повторюсь немного. Системы распознавания образов развиваются очень быстро и довольно давно, я полагаю еще с времен, когда появились первые камеры слежения. У меня есть знакомый, который и диссертацию защищал по этой теме, и долго работал в каком-то НИИ, опять же, над той же темой. Так что вычленить всех собак или кошек, молотков или танков, и т.п. я думаю, им (врагам) скоро не составит труда. Это была моя первая мысль, когда я только начал задумываться о том, как же запутать следы. Поэтому я и решил эту задачу усложнить не столько пользователям, сколько роботам, конечно. Кстати, моя пробная, опытная база данных, вполне вероятно, очень далека от совершенства. Эти 8 категорий могут быть совсем другими, может быть, более понятными людям. На то и существует моя утилита — хозяин базы сам ее (базу) может спроектировать и легко сформировать. Так что, усложнение — это дань надежности. Дальше нужно искать ту грань, которую мы все ищем на протяжении всей нашей жизни, т.е. ‘сытые волки, целые овцы’. Надеюсь, что эта грань выкристаллизуется по мере развития плагина (если он кому-то приглянется, конечно).
Вопрос, Дима, в развитие того, что Вы сказали в своём предыдущем ответе Владимиру и мне.Вы говорите, что Ваша инструментальная утилита работает 30 сек. А сколько дней, в среднем, уйдёт на создание собственной базы данных с собственными картинками? Ведь картинки человек должен искать сам. Неужели за три рабочих человека/дня всё это можно сделать, а потом также легко всё это изменить и сделать заново с чистого листа?
Анатолий, картинки я нашел в Гугле, причем целыми ‘пачками’,
по 20-25 картинок на странице. Потом скриншот, потом фиксированный selection в Gimp’e 150×150 пикселей и ‘нарезка’ кусочков. Самым нудным делом оказалось называть файлы 🙂 Мне нужно было их называть с привязкой к содержанию, и то только потому, что программа была не отлажена (даже не запущена еще). Сейчас имена файлов могут быть 0001, 0002 и т.п.
Кстати, при этом я еще и работал. Я, конечно, не образец среднего пользователя, кое-какой опыт с версткой у меня есть, но, думаю, даже если это будет не 3 дня, а 5, все равно игра стоит свеч. Главное — это спроектировать систему категорий и подкатегорий. Ну, и это только когда/если роботам таки удастся взломать опытную БД. Имея дерево подкаталогов на диске, хозяин БД получит ее, запустив утилиту, за считаные секунды. Далее, можно не менять все файлы, а просто добавлять/менять картинки в нужный/ом подкаталог/е и перезапускать утилиту — БД пересоздастся заново.
Дима, а Вы предполагаете поставку начальной БД со своими категориями, подкатегориями и картинками? Будет ли приложено руководство для администратора по её развитию и модификации?
Если искать задачи, которые людям легки, а роботам тяжелы, то не подойдут ли в качестве фильтра тестовые вопросы типа «есть ли футбольная команда на Марсе?»
А как, с Вашей точки зрения, должен на этот вопрос ответить нормальный человек, чтобы его не спутали с роботом? Не будет ли это ещё сложнее для «тупого», но зато живого пользователя?
Я думаю нормальный человек без труда скажет «нет» )) Другое дело, что робот может выбрать случайный ответ и в половине случаев угадает. Тогда нужно два вопроса и т. д. :))
Я поэтому и задал этот вопрос. Боюсь, что при любом «и т.д.» роботу -автомату не составит большого труда методом перебора правильно ответить на все подобные вопросы.
Кстати, Дима, а что насчёт возможного автоматического перебора и нахождения нужного варианта в случае Вашего плагина?
Тестовые вопросы на отделение человека от компьютера (т.н. Тюринг тест) начались разрабатываться еще в 50-е годы. Отсюда и название CAPTCHA — Completely Automated Public Turing test to tell Computers and Humans Apart. Привожу ссылку на статью из Википедии: http://en.wikipedia.org/wiki/CAPTCHA
Там же, кстати, обнаружил интересную информацию о еще одной image-based CAPTCHA, от Гугла — пользователю/роботу предлагается определить, какая из картинок перевернута ‘вверх тормашками’.
Автоматический перебор 2-х картинок из 9-и — это факториал 9 поделенный на произведение факториала 2 и факториала 7, т.е. всего 36 комбинаций. Не так уж и много, конечно, но я предполагаю ввести ограничение на неудачные попытки с одного IP адреса. Пока думаю, какой алгоритм реализовать, чтобы ‘не выплеснуть с водой ребенка’, т.е. чтобы не отсечь по ошибке живых людей.
Перед своим основным вопросом, давайте, Дима, на примерах уточним, что Вы называете категорией и подкатегорией. Сколько может быть категорий, и сколько подкатегорий в каждой? Есть ли ограничение на общее количество картинок в Базе Данных?
Анатолий, с Вашего позволения начну с конца. Ограничений нет как на количество картинок, так и на количество подкатегорий (последних может вообще не быть, как у меня сейчас с «Geometry» и «Plants»). Категорий в текущей имплементации должно быть на одну меньше, чем показываемых картинок, т.е. в данном варианте (2 из 9) — 8 штук. Категория — это укрупненное множество каких-либо объектов, которое может быть разбито на более специфические подмножества-подкатегории (желательно, но необязательно). Один из примеров — категория «Посуда» может быть разбита на «Тарелки», «Чашки», «Вилки» и т.д. Основная задача при проектировании БД — это постараться четко ‘отстроить’ одну категорию и подкатегорию от другой и учесть, насколько каждая подкатегория выразительна на экране. Например, начав собирать картинки в категорию «Профессия», я бросил это занятие после получаса — уж слишком расплывчаты были границы, к тому же не всегда было ясно, кто на картинке — космонавт или пожарник. А в-остальном — полная свобода творчества для хозяина БД (если он ее захочет, конечно 🙂 ).
А что, формула «2 из 9» тоже может быть изменена?
Да, довольно легко на программном уровне; чуть сложнее вывести это на уровень параметров, т.е. для управления пользователем. Я исходил из ‘презентабельности’ матрицы 3х3 и дизайна БД — для 2 из 16 уже понадобится не меньше 15 основных категорий.
Анатолий, Дмитрий, с радостью попробую помощь Вам.
Попробую что-нибудь дельное написать.
1) На мой взгляд хорошо бы поправить(раз речь о WP, т.е. плагин очень узко заточен под WP) — валидацию формы до отправки.
Я нажимаю на «Оставить комментарий», при этом не ввел Имя — происходит переход и только там я вижу ошибку. Думаю повесить на submit пару функций не составит большого труда.
2) Пока еще не могу с 100% указать где именно ошибка, т.к. не всегда могу поймать баг. Суть такая — читаю статью, минут примерно 5-10, затем пишу текст комментария, ввожу 2 одинаковых «инструмента», нажимаю «Оставить комментарий», на выходе получаю ошибку — «RUH Captcha: Что-то не так! Похоже, Вы ошиблись в выборе. Попробуйте ещё раз. Если Вы уверены, что все делаете правильно, пожалуйста, напишите мне по адресу amilner-at-itechbridge-dot-com. Спасибо.
….».
Есть подозрение, что token протухает по TTL.
Шаг1 — http://gyazo.com/5b35a2a8292cdf92416ad5c115c77ee4, шаг2(после сабмита) — http://gyazo.com/8076d2e7cfb62b9c42c5c3880e1f7916
3) «Увеличить:x0__ x2__ x3_» — связать label к соответствующему radio button(в текущей реализации это тег span).
Далее минорные замечания(из серии — ну может же быть лучше:) ).
4) Поправить верстку — http://gyazo.com/f37918911d3e8b0dfa0bde581b907640
Желательно отказаться от тегов root, data. html5 это хорошо, но пока(для такой задачи) можно и без него. Так же title у div.
5) Уменьшить кол-во скриптов для работы каптчи. 4-5 скриптов, причем таких тяжелых, думаю много.
6) Перевести все на нативный js, т.е. отказаться от jquery. И сжать все это через тот же Closure Compiler.
7) Обязательно использовать data:image/gif;base64 ?
P.S. Интересно будет поковырять более подробно. Постараюсь на выходных найти время, что бы погонять посложней тесты(разные браузеры, нагрузка и т.д.).
Спасибо, Александр! Это лично от меня. Ну, а думаю, Дмитрий Вам как профессионалу и одновременно тестеру-волонтиру скажет большое спасибо:)
Александр, по пункту 2, извините, только что посмотрел картинки. Если не ошибаюсь, там в нижнем ряду две кошки. Если это так, то они — более предпочтительный вариант, чем инструменты, так как кошки в одной подкатегории «Cats» из категории «Animals», а напильник и молоток — в разных: «Files» и «Hammers», соответственно.
Александр, даже не большое, а огромное спасибо!
Буду работать над замечаниями и постараюсь отловить баг.
Да, WP — это первый шаг, я еще хочу к Drupal’у его прикрутить, так что очень ценные замечания, спасибо еще раз.
А теперь обещанный основной, но не последний:) вопрос, а точнее, серия связанных между собой вопросов. Можете ли Вы всё-таки на уровне одной патентоподобной фразы сформулировать суть Вашего новшества? Или Вы не хотите раньше времени это делать? Если так, то собираетесь ли Вы патентовать свою технологию? И в таком случае тогда попытайтесь на потребительском уровне, но тоже одной-двумя фразами объяснить основную особенность Вашего подхода.
Анатолий, конечно, хочется запатентовать и вывести проект на коммерческий уровень. Но, как линуксоид, обязуюсь также поддерживать бесплатную версию на приемлемом полезном уровне, включая, по мере сил и возможностей, тех. поддержку и FAQ страницу.
Понятно, но тогда повторяю: хотелось бы всё-таки, если возможно, получить без разглашения коммерческой тайны в одном или двух предложениях описание самой принципиальной отличительной особенности Вашего проекта. В исходном материале, мне показалось, это сделано несколько «размазано».
И тут же второй вопрос по ходу. Бизнес-модель проекта. Как и на чём собираетесь зарабатывать?
Анатолий,
Как мне кажется, основных особенностей как минимум две:
1). Усложнение автоматического нахождения правильного ответа за счет введения дополнительного логического уровня для соответствия объектов. При этом роботу неизвестно, на каком уровне он находится — то ли ему нужно искать двух лягушек, то ли лягушка с лошадью сейчас — правильный ответ.
2). Легкость изменения/дополнения базы данных объектов. Если сайт находится под постоянными атаками, если кто-то купил ‘попок’, собирающих базу по кусочкам, все равно регулярное изменение базы всегда будет опережать спамеров, IMHO
Насчет Бизнес-модели пока не ясно, пока начну с банального Donate, дальше жизнь покажет, надеюсь.
На счет image-based каптчи. Есть некий проект — https://www.keycaptcha.com/ . У них неплохо реализована идея, если я не ошибаюсь, они первые в своем роде. Пользователю необходимо перетащить нужный блок, что бы собрать общую картинку. Напоминает пазл.
Идея RUH конечно интересная. Причем логи показывают что ботов каптча останавливает. Как дополнение — подумать над дизайном и сделать вариант lite. Что то вроде уменьшенной копии каптчи, что бы текст был скрыт за спойлером.
P.S. Дмитрий, Вы так и не ответили по пункту 7.
Александр,
Извините за 7-й пункт, упустил из виду.
Embedded картинки делать, конечно, не обязательно, это просто для удобства и переносимости базы. Все картинки лежат в ней, безымянные. В какой-то image-based каптче (если не ошибаюсь, Animal captcha плагин для WP) имя картинки содержит ответ, чего я точно не хочу. У меня был вариант с временными именами, но тут возникает проблема с пересечением запросов (я делал папки с именами айпи, но это не 100% уникальность, теоретически могут быть несколько вхождений с корпоративного айпи одновременно). Хранить картинки отдельно от базы очень не хочется.
А что Вы предлагаете?
Если все же в ТЗ есть пункт, что картинки должны быть в базе, то Ваш вариант конечно предпочтительней.
Если нужна аудитория пользователей ИЕ6-7, тогда для них все же придется, что то придумать. Т.к. у них http://gyazo.com/78e74e5d9617ada521f66eee07cdb135 все не так сладко как для Хрома последнего или FireFox.
Одно из кардинальных решений — отдавать на клиента склеенный из 9 различных картинок один sprite. При клике определять координаты той картинки, на которую от кликнул в sprite и передавать их на сервер. Сервер знает, к примеру, что отдал sprite_1 — значит правильных может быть только N решений, а именно правый верхний угол(координаты 30,0 — кошка) и нижний центральный(координаты 20,30 — еще одна кошка). Если ему пришли отличные от этих координат — значит выбрали не верно.
Логику, кликнули по правильным картинкам или нет, можно переложить на клиента, передав вместе со sprite координаты «правильных» картинок. Тогда будет решен п.1(по поводу валидацией перед отправкой, правда логов с ошибочными вводами не получить. Хотя можно через тот же ajax, jsonp это все сделать — и логи собрать и на клиенте обыграть, без перезагрузки)
Идея понята?
Посколько все пункты в ТЗ, насколько я понимаю, Дима сам и писал, то ему придется нам и рассказать, почему такой «пункт» там появился?:)
Александр, спасибо еще раз за тестирование и интересные соображения.
ТЗ, как и предположил Анатолий, действительно писал я сам:)
В-основном я хотел добиться того, чтобы как можно меньше информации было доступно тем, кто начнет reverse engineering с целями, отличными от Вашей, т.е., не помогать, а ломать. Исходя из этих же соображений, на клиента логику перекладывать нельзя — взломают тут же:)
Идея со спрайтами понятна, спасибо, но тут вступает в силу UI, который и так без jquery вряд ли получится переносимым, а со спрайтами его и вовсе нужно будет переписать заново. Боюсь. что в обозримом будущем ни времени, ни сил на это не найдется у меня…
Попробую поставить 6-7 ie и посмотреть, в чем там все-таки дело, может, отделаюсь ‘легкой кровью’.
Александр, нашел, как обойти ie6-7: http://webo.in/articles/habrah.....-data-url/
Постараюсь реализовать.
Да, очень симпатичная каптча, спасибо, Александр. И за идею скрытия текста тоже спасибо — буду работать над этим
Дима, спасибо за подробные ответы. Лично мне, практически всё стало значительно яснее, хотя говорим мы об этом уже давно. Сейчас же возникло даже некоторая неловкость — а не слишком ли детально я у Вас всё на публике вытягивал? Как Вы, вообще, хотите совместить дальнейшее продвижение своего проекта с сохранением авторских прав на своё изобретение? Ведь патент, как я понял, появится не завтра, а продвигать проект Вы уже начали сегодня:).
Анатолий, надеюсь, авторское право у меня не отнимут. Если я не ошибаюсь, оно (АП) автоматически вступает в силу после первой публикации, за что (публикацию) снова хочу сказать Вам спасибо.
С патентом сложнее, это дорогое и трудоемкое удовольствие. Время покажет, стОит ли этим заниматься.